On Friday, June 29, 2007
Aubrey Huff first baseman for the
Baltimore Orioles hit for the cycle. In one game, he had a single, a double, a triple, and a homerun. This has happened 276 times in major league history, only three times for the Baltimore Orioles and it is the first time it has happened at home in Baltimore and at Oriole Park at Camden Yards. In the major leagues he is the third player to
hit for the cycle in 2007. So what is the distribution of such an event?
Interestingly, just this year Huber and Glen have modeled the distribution of such rare events in their article,
“Modeling Rare Baseball Events – Are They Memoryless?” in the
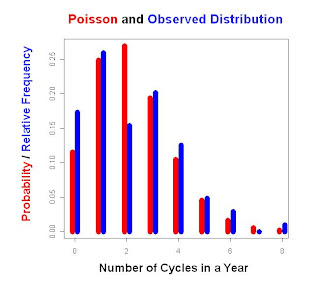
Journal of Statistics Education. They model three baseball events as a Poisson Process: no-hit games, triple plays, and hitting for the cycle. Using data from 1901 through 2004 they get the distribution shown above of how many cycles are seen in a given season. The observed results are a bit short on seasons with exactly 2 players hitting for the cycle, and there are a few more seasons than expected with exactly 1 player hitting for the cycle. The expected results are shown in red: a Poisson distribution with the observed mean of 2.19.
Over the time period examined, nearly 160,000 games were played, and only 0.14% of these games had a player hit for the cycle. As Huber and Glen found the cycle is rarer than a triple play but not as rare as a no-hitter.
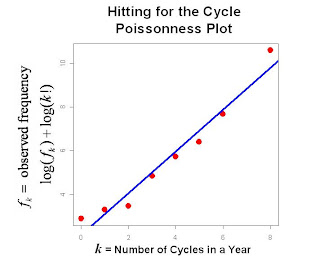
So how closely does this match a Poisson process? One measure is a Poissonness Plot developed by Hoaglin (American Statistician 1980). If f[k] represents the observed frequency of a random count k then the log of the Poisson density would essentially be -λ+klog(λ)-log(k!). So that in a plot of log(f[k])+log(k!) against k, a straight line would indicate a good fit to a Poisson distribution. The slope of this line is an estimate of log(λ). Here log(λ) is 0.9583, so that an estimate of λ is 2.607. Of course the maximum likelihood estimate is simply the mean number of cycles per season 2.19. Since the variance of a Poisson distribution is also equal to λ, this would provide another estimate of 2.90. Note the Poissonness plot estimate falls in between the two.
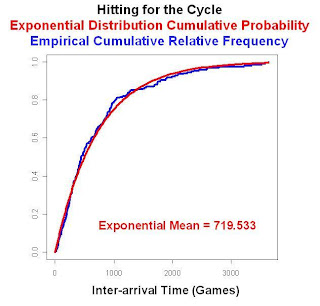
Another way of checking for a Poisson process is to check the inter-arrival times, that is, the number of games between any two players hitting for the cycle. These inter-arrival times should follow an exponential distribution. The figure below shows the cumulative relative frequency of the observed time between cycles for the period 1901 through 2004. Also shown is the theoretical exponential cumulative probability distribution with a mean equal to the observed mean of 719.533 games. This indicates that the cycle process is memoryless. Even if there have been 1000 games without any major league player hitting for a cycle, you would still have to wait on average over 719 games more before one does.
For Aubrey Huff it was certainly a special night. Not only did he hit for the cycle he also had the 1000th major league hit and the 200th double of his career. Even with all that the Orioles still lost the game to the LA Angels 9 to 7.









