

Devoted to images that illustrate statistical ideas
Monday, February 29, 2016
Scattered Dimples
Monday, February 22, 2016
Scuff and Wear

Monday, February 15, 2016
Mesmerizing Movement


Eating, work, housework, and even leisure dominate this lunch hour view. See more here.
Monday, February 8, 2016
Correlation Guessing
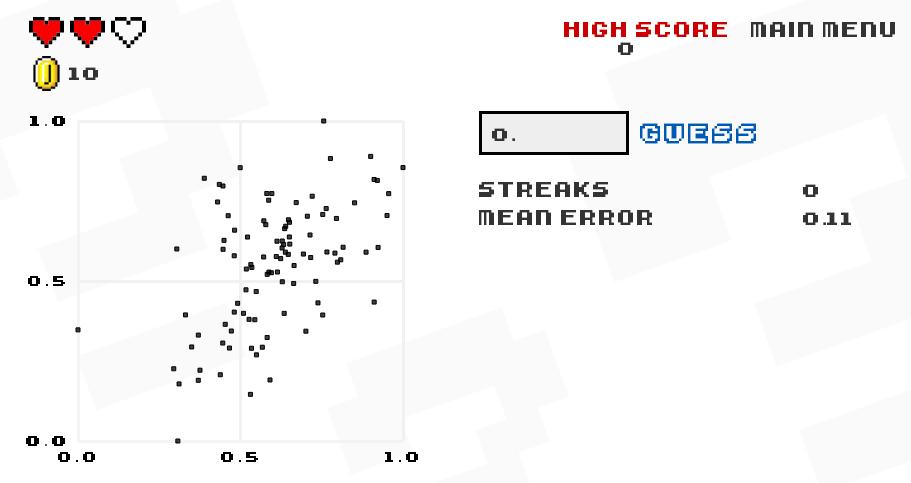
(With the 8-bit graphics, this game looks like it was made in the 1980s for the Mario Brothers).
Monday, February 1, 2016
Learning The Alphabet


Mean of all the output fonts.

Median of all the output fonts.
Note how readable the mean and median fonts are, when the individual input fonts are extremely varied, as shown above in the first image. He goes on to interpolate fonts, apply random perturbations, and even generate new fonts by sampling from a multivariate normal distribution of the font vectors.
A mean of a collection of fonts we have seen before using a technique of simple visual averaging.
Subscribe to:
Posts (Atom)